CNN vs Transformer, quantized: YOLO26-seg and RF-DETR-Seg race for instance masks on an Intel iGPU
Two opposite small segmentation models — a 2026-era CNN and a DETR transformer — both quantized to INT8 with NNCF and run on a laptop Intel iGPU. YOLO26-seg's forward pass is ~7.4× faster; RF-DETR-Seg keeps its masks more faithful under INT8. The whole shootout, numbers first.

A 2026-era CNN and a DETR transformer, both quantized to INT8 and run on the laptop iGPU you already own. On an Intel Iris Xe, YOLO26-seg’s forward pass is ~2.1× faster at INT8 than at FP32 on the same iGPU (9.3 ms, ~107/s) — and ~7.4× faster than RF-DETR-Seg. But the transformer keeps its masks more faithfully under INT8 (0.95 vs 0.87 IoU). And weight-only INT8? Zero iGPU speedup. Here’s the whole shootout.
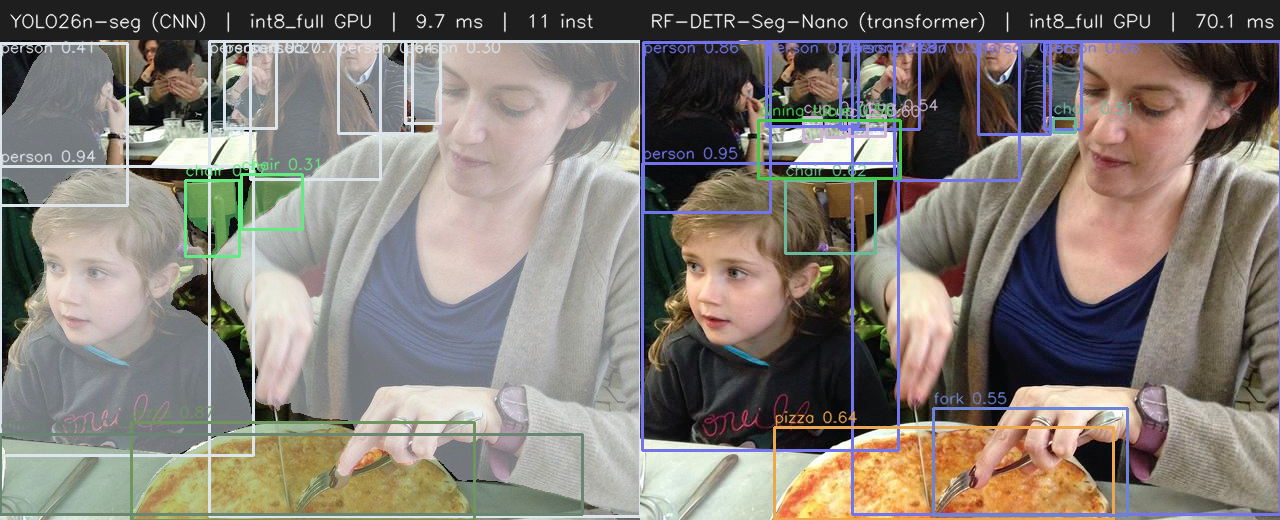 Same frame, both at INT8 on the Intel iGPU. Left: YOLO26n-seg, ~9.7 ms. Right:
RF-DETR-Seg-Nano, ~70 ms. The CNN is an order of magnitude cheaper per frame.
Same frame, both at INT8 on the Intel iGPU. Left: YOLO26n-seg, ~9.7 ms. Right:
RF-DETR-Seg-Nano, ~70 ms. The CNN is an order of magnitude cheaper per frame.
Why bother doing this on an iGPU?
Instance segmentation — a mask per object, not just a box — is the expensive end of real-time vision. The reflex is to reach for an NVIDIA GPU. But most laptops, mini-PCs and industrial edge boxes ship with an Intel integrated GPU sitting idle, and OpenVINO turns it into a real inference accelerator for free: no cloud, no discrete card, no per-frame egress cost.
The open question for a practitioner is which model family. Two strong, very different small seg models landed in early 2026:
- YOLO26n-seg — Ultralytics, a CNN, NMS-free and DFL-free, 640×640.
- RF-DETR-Seg-Nano — Roboflow, a DETR transformer (DINOv2 backbone), 384×384.
CNN vs transformer, same iGPU, one shared INT8 pipeline. Which wins on latency, and do the masks survive quantization? This is a segmentation sequel to earlier detection benchmarks — same hardware, now with masks.
The approach in one flow
coco128-seg → export each model to OpenVINO FP32 IR → one NNCF pipeline
→ {weight-only INT8, full-PTQ INT8} per model
→ benchmark forward latency + mask-IoU retention on {CPU, iGPU}- Models:
yolo26n-seg.pt(Ultralytics) andRFDETRSegNano(Roboflow), nano tier. - Data:
coco128-seg(128 COCO images with masks) — calibration and eval. - Runtime: OpenVINO 2026.2, NNCF INT8.
- Hardware: Intel Core i7-12700H — Iris Xe iGPU (
GPU.0) and the CPU.
Everything is a uv run seg-<verb> command; the whole thing reproduces from
uv sync.
Build walkthrough
1. Export — two export paths, one IR layout
The two families could not export more differently. YOLO26 exports to OpenVINO in
one Ultralytics call; RF-DETR goes through ONNX and ov.convert_model
(cli/export.py):
# YOLO26: Ultralytics emits the IR folder directly
YOLO("yolo26n-seg.pt").export(format="openvino", imgsz=640, half=False, dynamic=False)
# RF-DETR: export ONNX (opset 18, static shape) → convert to OpenVINO IR
model = RFDETRSegNano()
model.export(output_dir=tmp, opset_version=18, shape=(res, res))
ov_model = ov.convert_model(onnx_path)Two gotchas surfaced immediately, both worth knowing:
YOLO26 is end-to-end. Its seg export does not produce the legacy
(1, 116, 8400) raw grid. Being NMS-free, it emits (1, 300, 6 + 32) —
up to 300 already-deduplicated instances, each
[x1, y1, x2, y2, conf, cls, 32 mask coeffs], plus a (1, 32, 160, 160)
prototype bank. No NMS, no transpose — just threshold and assemble masks
(core/yolo26.py):
det = det[0] # (300, 38): [x1,y1,x2,y2,conf,cls,coeffs]
boxes, conf, cls, coeffs = det[:, :4], det[:, 4], det[:, 5], det[:, 6:38]
masks = sigmoid(coeffs @ proto.reshape(nm, mh * mw)).reshape(-1, mh, mw)RF-DETR’s mask head won’t trace through the legacy ONNX exporter. It
upsamples with antialiased bicubic (aten::_upsample_bicubic2d_aa), which the
TorchScript exporter can’t emit. We disable antialiasing just for the export
trace — masks are thresholded afterward, so the effect is nil:
def _no_antialias(*args, **kwargs):
if kwargs.get("antialias"):
kwargs["antialias"] = False
return orig_interpolate(*args, **kwargs)The RF-DETR IR then emits three tensors: boxes (1, 100, 4), logits
(1, 100, 91) (COCO’s sparse 1-90 indexing, not contiguous-80 like YOLO), and
mask logits at a compressed (1, 100, 96, 96). Those low-res logits must be
bilinearly upsampled before thresholding — the documented RF-DETR gotcha,
handled in core/rfdetr.py:
up = cv2.resize(mask_logits[q], (orig_w, orig_h), interpolation=cv2.INTER_LINEAR)
mask = sigmoid(up) >= 0.52. Quantize — one NNCF pipeline for both
The fair-comparison move: instead of letting each framework quantize its own way,
both FP32 IRs go through the same NNCF code
(cli/quantize.py), with weight-only
(compress_weights) and full PTQ (nncf.quantize calibrated on coco128-seg).
The only per-model difference is the preset — RF-DETR, being a transformer, gets
ModelType.TRANSFORMER so SmoothQuant [4] protects its attention and LayerNorm:
kwargs = {"model_type": nncf.ModelType.TRANSFORMER} if name == "rfdetr" else {}
quantized = nncf.quantize(core.read_model(src), nncf.Dataset(tensors), **kwargs)Calibration reuses each model’s inference preprocessing (YOLO letterboxes; RF-DETR squashes + ImageNet-normalizes), so the quantized path sees the exact input distribution it will see at runtime.
3. The device-family trap
get_available_devices() returns GPU.0 / GPU.1, never a bare GPU. A naive
"GPU" in available check fails, silently falling back to CPU — so your “iGPU”
benchmark is really a CPU benchmark. The resolver in
core/common.py matches families:
if any(d == requested or d.startswith(requested + ".") for d in available):
return requestedOn this machine GPU.0 is the Intel Iris Xe (our target) and GPU.1 is a
discrete NVIDIA card OpenVINO also enumerates — GPU correctly resolves to the
iGPU.
Results
Speed is the raw OpenVINO forward latency — the part quantization actually accelerates, measured identically for both families (mask post-processing is CPU-side Python either way). Each cell is the median of 3 runs of 50 timed passes after warmup, batch 1.
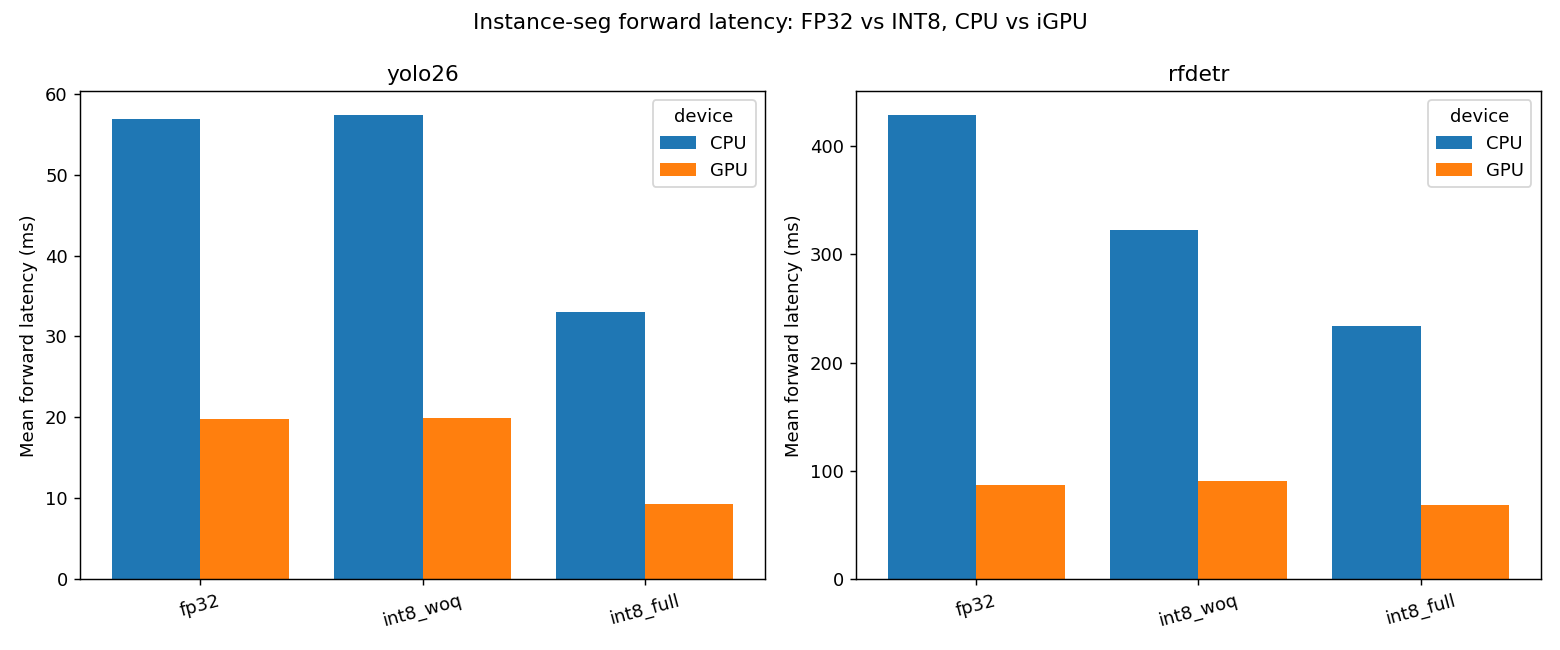
Speed — FP32 vs INT8, CPU vs iGPU
| model | precision | device | mean ms | p50 ms | p90 ms | img/s |
|---|---|---|---|---|---|---|
| yolo26 | fp32 | CPU | 56.89 | 35.47 | 101.95 | 17.6 |
| yolo26 | fp32 | GPU | 19.74 | 19.20 | 21.52 | 50.7 |
| yolo26 | int8_woq | CPU | 57.42 | 34.77 | 103.93 | 17.4 |
| yolo26 | int8_woq | GPU | 19.96 | 19.53 | 21.95 | 50.1 |
| yolo26 | int8_full | CPU | 32.98 | 17.22 | 64.94 | 30.3 |
| yolo26 | int8_full | GPU | 9.32 | 9.36 | 9.52 | 107.3 |
| rfdetr | fp32 | CPU | 429.18 | 302.36 | 730.56 | 2.3 |
| rfdetr | fp32 | GPU | 86.61 | 85.63 | 91.65 | 11.5 |
| rfdetr | int8_woq | CPU | 322.23 | 193.74 | 596.09 | 3.1 |
| rfdetr | int8_woq | GPU | 90.75 | 87.33 | 102.95 | 11.0 |
| rfdetr | int8_full | CPU | 233.51 | 142.05 | 430.10 | 4.3 |
| rfdetr | int8_full | GPU | 68.81 | 66.46 | 77.43 | 14.5 |
Mask quality retention (INT8 vs FP32 reference)
Foreground-mask IoU of each INT8 model against its own FP32 output, over 30 coco128-seg images, plus the mean instance count. (Computed in ACCURACY execution mode — see Measurement notes for why that matters.)
| model | precision | mask IoU vs fp32 | mean #inst | fp32 #inst |
|---|---|---|---|---|
| yolo26 | int8_woq | 0.959 | 4.5 | 4.4 |
| yolo26 | int8_full | 0.870 | 3.5 | 4.4 |
| rfdetr | int8_woq | 0.958 | 4.5 | 4.5 |
| rfdetr | int8_full | 0.950 | 4.4 | 4.5 |
The headline numbers
I lead with same-device ratios, because those are the stable signal — the CPU baseline on this P/E-core part is noisy (see Measurement notes).
- Full INT8 is ~2.1× faster than FP32 on the same iGPU (9.32 vs 19.74 ms) — the clean, apples-to-apples quantization win.
- YOLO26 is ~7.4× faster than RF-DETR at INT8 on the iGPU (9.32 vs 68.81 ms), despite running at 640 while RF-DETR runs at 384.
- In absolute terms that’s ~107 forward passes/s on the iGPU for YOLO26. Versus the CPU it’s very roughly 3.5–6×, but treat the CPU multiplier as a ballpark — its latency distribution is heavily tail-skewed on this machine.
Measurement notes
A few things to read the tables honestly — and to reproduce them fairly:
- Forward-only. Latency and “img/s” are the raw OpenVINO forward pass (batch 1), not end-to-end FPS. Mask assembly (prototype matmul / query upsampling) and NMS-free decode run in CPU Python on top, so real per-frame FPS is lower. Forward-only is deliberate: it isolates what quantization actually changes and measures both families identically.
- Run-to-run variance. Each cell is the median of 3 runs, but the iGPU forward latency still moves ±10–20% across runs (thermal + whatever else the laptop is doing) — FP32-iGPU in particular drifted between 19.7 and 21.6 ms across my runs. The same-device ratios are the stable signal — lean on them, not the third decimal.
- Quality eval runs in ACCURACY mode for a reason. Speed uses the deployment-realistic PERFORMANCE hint (reduced precision — where INT8 gets its iGPU win). But PERFORMANCE mode can intermittently corrupt a weight-only-INT8 model’s outputs when the same IR was compiled on the GPU earlier in the same process — I caught it producing 300 garbage detections on one run. ACCURACY execution mode (full precision on non-INT8 ops) is immune and isolates the pure quantization effect, so all quality numbers use it. A real OpenVINO gotcha worth knowing if you mix devices in one process.
- mean vs p50. We report
mean. On the iGPU the distribution is tight so it barely matters; on the CPU it is tail-heavy (12700H P/E cores + thermal throttling), somean≫p50. If you compare devices,p50is the fairer central stat. - The RF-DETR decode is a simplified reimplementation. I do per-query
argmax + threshold; RF-DETR’s official post-processor does a global top-K over
the flattened (query × class) score matrix. I validated mine against the native
.predict()— instance counts land within ~0.4/image — so it’s faithful, but it is not bit-identical. The within-model INT8-vs-FP32 retention is unaffected either way (same decode on both precisions). - The mask metric is retention, not accuracy. “Mask IoU vs fp32” is the instance-agnostic foreground-union IoU against each model’s own FP32 output — it answers “does INT8 still draw the same masks?”, not “are the masks correct?”. Absolute quality would need a COCO mask-mAP run.
- Confidence thresholds differ (YOLO 0.25, RF-DETR 0.5 — each family’s native default), so cross-model instance counts (4.4 vs 4.5) aren’t directly comparable; the per-model retention is.
The honest findings
1. Weight-only INT8 buys you nothing on the iGPU. YOLO26 weight-only is 19.96 ms vs 19.74 ms FP32 — indistinguishable. RF-DETR weight-only is actually slower on the iGPU (90.8 vs 86.6 ms): the on-the-fly weight decompression costs more than it saves when activations stay FP. Only full PTQ (activations quantized) unlocks the iGPU’s INT8 math. Weight-only still has a place — it shrinks the model and helps a little on CPU — but it is not your iGPU speed lever.
2. INT8 helps the CNN far more than the transformer on the iGPU. YOLO26 gets a clean ~2.1× from full INT8 on the iGPU. RF-DETR gets only ~1.26× (86.6 → 68.8 ms). Most of RF-DETR’s win comes simply from being on the iGPU at all (CPU 429 ms → iGPU 87 ms); its attention matmuls and the einsum mask head don’t accelerate much under INT8. If you picked RF-DETR expecting INT8 to close the gap to YOLO, it doesn’t.
3. The surprise: the transformer keeps its masks better. I expected DETR’s
quant-sensitive attention to degrade masks more. The opposite happened —
RF-DETR-Seg held 0.95 foreground-mask IoU under full INT8 while YOLO26 fell to
0.87, dropping from 4.4 to 3.5 instances per image (it loses marginal-confidence
objects). NNCF’s TRANSFORMER preset (SmoothQuant) earned its keep. So the choice
is a genuine trade-off: YOLO26 for raw speed, RF-DETR when INT8 mask fidelity matters.
4. Resolution caveat, stated plainly. YOLO26 runs at 640 and RF-DETR at 384 — their native sizes. Even with that handicap the CNN is ~8× cheaper per frame, so the speed verdict is robust; but the IoU and instance-count numbers are each-model-vs-its-own-FP32, not cross-model accuracy, which would need a COCO mAP run.
Reproduce it
uv sync
uv run seg-download # coco128-seg
uv run seg-export --model all # FP32 IR for both
uv run seg-quantize weight-only --model all
uv run seg-quantize full --model all # the iGPU speed lever
uv run seg-benchmark --devices CPU,GPU # tables + latency.png
uv run seg-compare --precision int8_full --device GPU # the hero imageStack: Python 3.11, ultralytics 8.4.56, rfdetr 1.7.x, OpenVINO 2026.2,
NNCF, torch 2.12. Hardware: Intel Core i7-12700H, Iris Xe iGPU. Every number
above comes from output/benchmark.md / speed.csv produced by seg-benchmark.
Takeaways
- On an Intel iGPU, full-PTQ INT8 is the speed lever; weight-only is not. Always quantize activations if latency is the goal.
- YOLO26-seg is the speed king at the nano tier — ~107 forward passes/s on a laptop iGPU (forward-only; see Measurement notes), no NVIDIA in sight.
- RF-DETR-Seg trades speed for mask fidelity under INT8 (0.95 vs 0.87 IoU). Pick by your budget: throughput → YOLO26; mask quality under quantization → RF-DETR.
- Match the export to the model. YOLO26 is end-to-end (no NMS to write); RF-DETR needs the antialias-export workaround and explicit mask upsampling.
- Next: push the same two models onto the Intel NPU, and add a COCO mask-mAP pass to turn “IoU vs FP32” into absolute accuracy.
For how mask-IoU and mask-AP are defined, see the segmentation metrics primer.
Further reading
- Go deeper: Szeliski, Computer Vision (2nd ed.) §5.5 (segmentation) and §5.5.4 (quantization).
- The technique: SmoothQuant (Xiao et al., 2023) + NNCF docs — transformer-aware post-training quantization.
- Related on CondadosAI: the detection prequel, RF-DETR vs YOLO-NAS at the edge; the metric definitions in segmentation metrics.
References
[1] Robinson, I., Robicheaux, P., Popov, M., Ramanan, D., & Peri, N. (2025). RF-DETR: Neural Architecture Search for Real-Time Detection Transformers. ICLR 2026. arXiv:2511.09554. GitHub.
[2] Jocher, G., et al. Ultralytics YOLO. Docs · GitHub. (YOLO26-seg.)
[3] Lin, T.-Y., et al. (2014). Microsoft COCO: Common Objects in Context. ECCV. arXiv:1405.0312. (coco128-seg subset.)
[4] Xiao, G., Lin, J., Seznec, M., Wu, H., Demouth, J., & Han, S. (2023). SmoothQuant: Accurate and Efficient Post-Training Quantization for Large Language Models. ICML. arXiv:2211.10438. (The technique behind NNCF’s TRANSFORMER preset.)
[5] Oquab, M., et al. (2023). DINOv2: Learning Robust Visual Features without Supervision. TMLR. arXiv:2304.07193. (RF-DETR backbone.)
[6] Szeliski, R. (2022). Computer Vision: Algorithms and Applications (2nd ed.), §5.5 (segmentation) & §5.5.4 (quantization for deployment). Springer. Free PDF.
[7] Intel. OpenVINO Toolkit and NNCF (Neural Network Compression Framework). Docs · NNCF.